Stable Diffusion——初识Stable Diffusion
什么是Stable Diffusion?
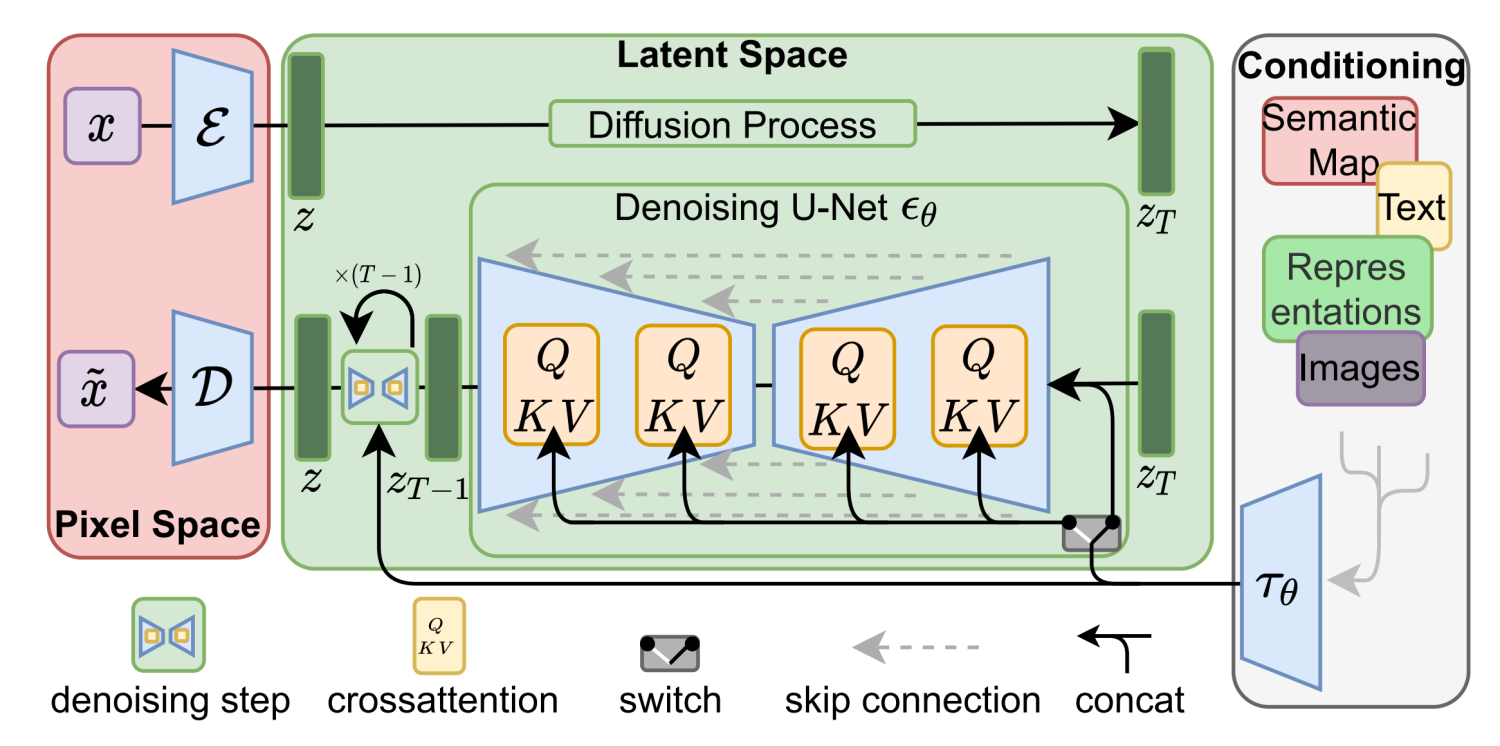
Stable Diffusion 算法上来自 CompVis 和 Runway 团队于 2021 年 12 月提出的 “潜在扩散模型”(LDM / Latent Diffusion Model),这个模型又是基于 2015 年提出的扩散模型(DM / Diffusion Model)。参考论文中介绍算法核心逻辑的插图,Stable Diffusion 的数据会在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转,其算法逻辑大概分这几步(可以按顺序对照下图):
- 图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
- 对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
- 通过 CLIP 文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
- 基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
- 图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
Stable Diffusion能做什么?
在最简单的形式中,Stable Diffusion 是一种文本到图像模式。给它一个文本提示。它将返回与文本匹配的图像(txt to image)。

扩散模型
Stable Diffusion 属于一类称为扩散模型的深度学习模型。它们是生成模型,这意味着它们旨在生成类似于他们在训练中看到的新数据。在稳定扩散的情况下,数据是图像。
为什么叫扩散模型呢?因为它的数学看起来很像物理学中的扩散。让我们来看看这个想法。
假设我训练了一个只有两种图像的扩散模型:猫和狗。在下图中,左边的两个峰代表猫和狗图像组。
正向扩散
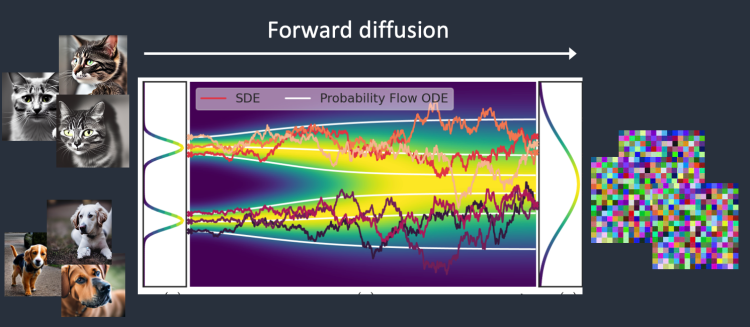
正向扩散过程会向训练图像添加噪声,逐渐将其变成异常噪声图像。前向过程会将任何猫或狗图像变成噪声图像。最终,您将无法分辨它们最初是狗还是猫。(这个很重要)
就像一滴墨水滴入一杯水中。墨滴在水中扩散。几分钟后,它随机分布在整个水中。你再也无法判断它最初是落在中心还是靠近边缘。
下面是一个图像正向扩散的例子。猫的图像变成了随机噪声。

反向扩散
现在是激动人心的部分。如果我们可以逆转扩散呢?就像向后播放视频一样。时光倒流。我们将看到最初添加墨滴的位置。
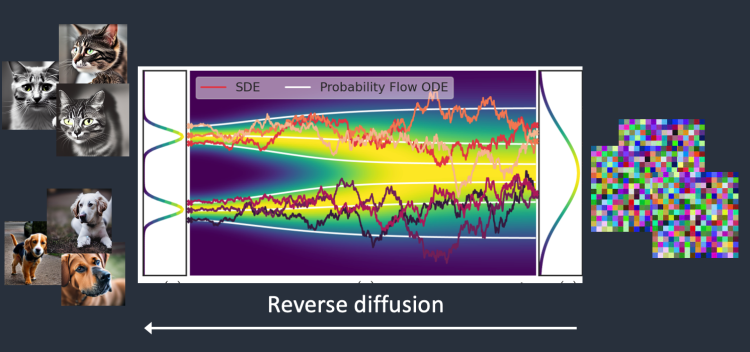
从嘈杂、无意义的图像开始,反向扩散恢复了猫或狗的图像。这是主要思想。
从技术上讲,每个扩散过程都包含两个部分:漂移和随机运动。反向扩散漂移到猫或狗的图像,但没有介于两者之间的图像。这就是为什么结果可以是猫或狗的原因。
这里的正向扩散,可以理解为将墨水滴入水杯中,墨水在水中散开的过程;
而反向扩散,则是将水杯中晕开的墨水还原到初始滴落点的过程。

当墨汁刚滴入水中时,我们能区分哪里是墨哪里是水,信息是非常集中的;当墨汁扩散开来,墨和水就难分彼此了,信息是分散的。类比于图片,这个墨汁扩散的过程就是图片逐渐变成噪点的过程:从信息集中的图片变成信息分散、没有信息的噪点图很简单,逆转这个过程就需要 AI 的加持了。
研究人员对图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。这个模型就是 AI 绘画中各种算法,如 Disco Diffusion、Stable Diffusion 中的常客扩散模型(Diffusion Model)。
模型是如何训练的?
反向扩散的想法无疑是巧妙而优雅的。但最重要的问题是,“如何才能做到?”
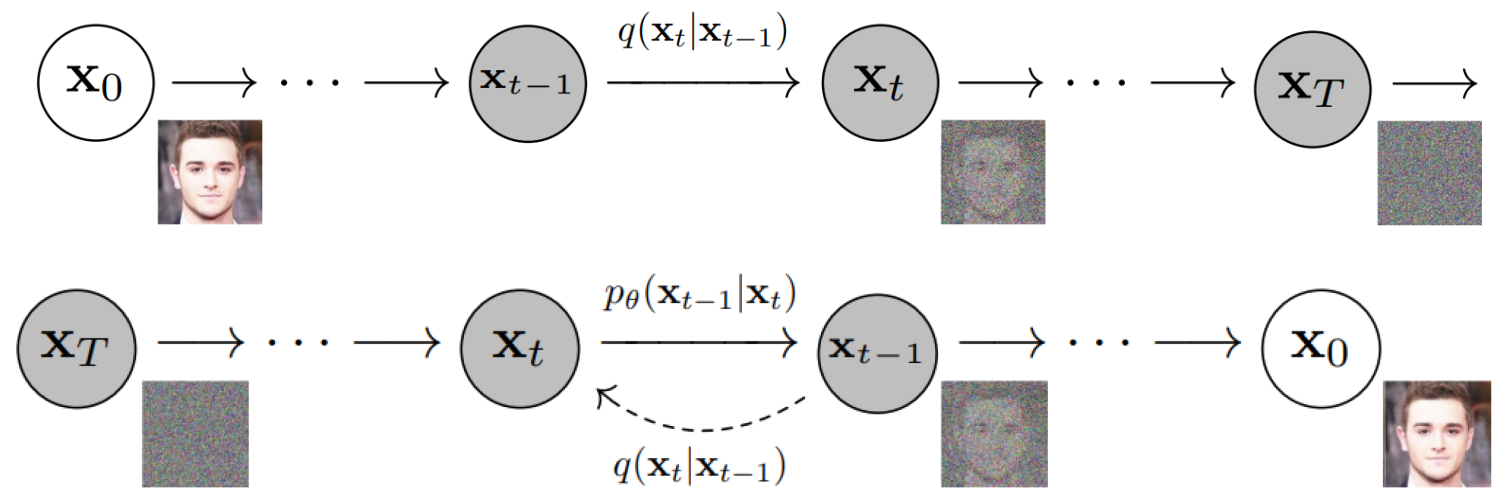
要反转扩散,我们需要知道图像中添加了多少噪声。答案是教一个神经网络模型来预测添加的噪声。它在 Stable Diffusion 中被称为噪声预测器。它是一个U-Net 模型。训练过程如下。
- 选择一张训练图像,比如一张猫的照片。
- 生成随机噪声图像。
- 通过将这个嘈杂的图像添加到一定数量的步骤来破坏训练图像。
- 教噪声预测器告诉我们添加了多少噪声。这是通过调整其权重并向其显示正确答案来完成的。
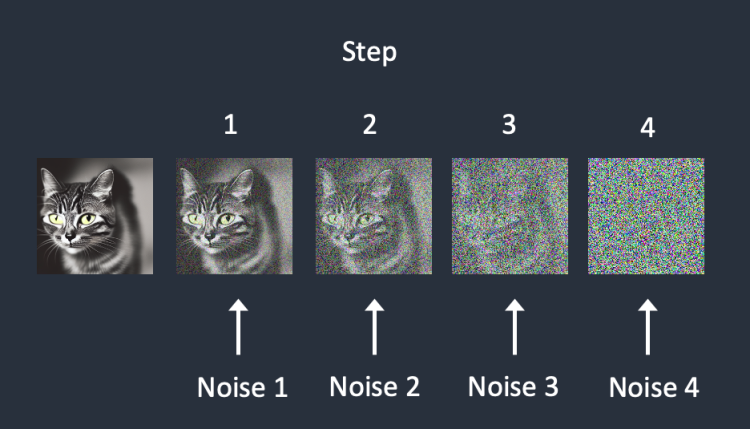
训练后,我们有一个噪声预测器能够估计添加到图像中的噪声。
反向扩散
现在我们有了噪声预测器。我们该如何去使用它?
首先生成一个完全随机的图像,并要求噪声预测器告诉我们噪声。然后我们从原始图像中减去估计的噪声。重复这个过程几次。您将获得一张猫或狗的图像。
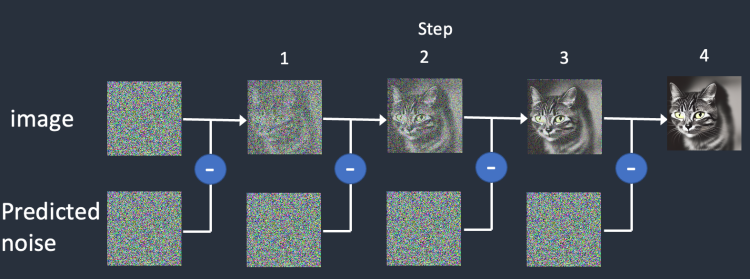
在当前的状态下,我们没有办法去控制Stable Diffusion生成的动物。如果要限定生成的内容,则需要用到Stable Diffusion的调节器配合提示词进行使用。
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。